
Appearance
Indexes
Les indexes sont les bases vectorielles qui rendent votre connaissance exploitable par l’assistant et les agents Hestyna.
Anatomie d’un index
- Source : l’intégration connectée (Confluence, Notion, Slack…).
- Service : le périmètre métier propriétaire de l’index.
- Filtre : le champ qui précise ce qu’il faut synchroniser (espace, base, canal, requête JQL…).
- Fréquence : cadence de synchronisation (manuelle ou planifiée).
- Statut :
Jamais,En cours,Terminé,Erreur.
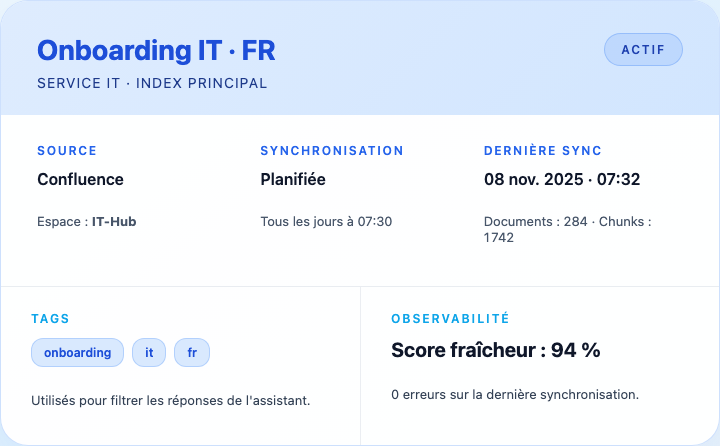
Ce qui est stocké
Chaque document est découpé en « chunks » avec les métadonnées suivantes :
organization_idservice_idsourcelanguagelast_synced_attagspersonnalisés (ex. site SharePoint, canal Slack)
Comment l’assistant s’en sert
- Identifie le service (via la demande ou le choix utilisateur).
- Sélectionne les indexes actifs associés.
- Recherche les chunks pertinents (via embeddings) et renvoie les citations.
- Affiche la source et la date de mise à jour pour transparence.
Maintenir des indexes fiables
- Surveillez Connaissance → Santé pour repérer les retards ou erreurs.
- Planifiez des synchronisations avant les grandes annonces (nouvelle politique RH, déploiement IT).
- Utilisez les filtres linguistiques pour différencier FR/EN/ES si besoin.
- Activez les notifications d’erreur vers Slack pour intervenir rapidement.
Archivage
- Passez un index en Désactivé pour le retirer des recherches sans supprimer l’historique.
- Supprimez les indexes obsolètes après export si vous n’en avez plus besoin.
À combiner avec : Documents