
Appearance
Documents
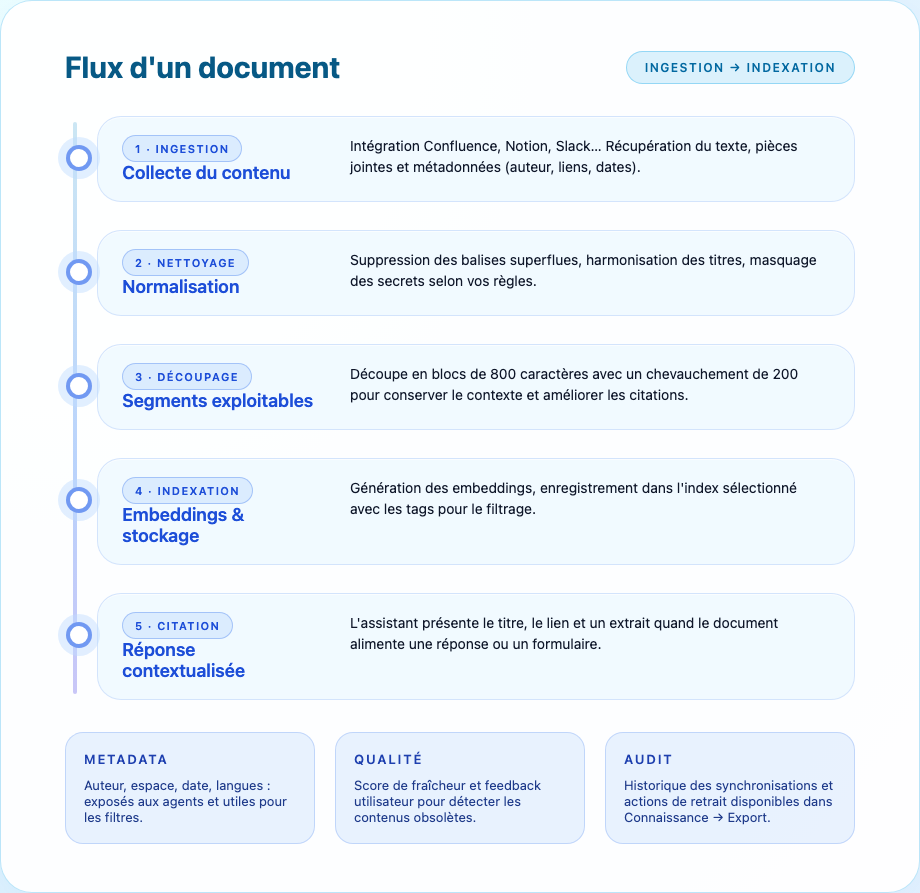
Les documents sont les éléments individuels indexés par Hestyna : articles Confluence, pages Notion, messages Slack, tickets Jira, etc.
Cycle de vie
- Ingestion : l’intégration récupère le contenu brut (texte, HTML, métadonnées).
- Nettoyage : normalisation (en-têtes, puces, tableaux), retrait des contenus sensibles si vous avez configuré des règles de masquage.
- Découpage : transformation en sections courtes avec recouvrement pour préserver le contexte.
- Indexation : calcul des embeddings et stockage dans l’index associé.
- Citation : lors d’une réponse, l’assistant affiche le titre et le lien du document.
Champs clés
| Champ | Rôle |
|---|---|
document_id | Identifiant unique (ex. ID de page Confluence). |
title | Intitulé affiché dans les citations. |
body | Contenu nettoyé, texte ou HTML autorisé. |
summary | Résumé généré automatiquement (utile pour les agents). |
language | Langue détectée ou forcée. |
tags | Métadonnées libres (service, produit, région). |
Bonnes pratiques
- Nettoyez à la source : corrigez les documents Confluence/Notion pour éviter de propager des erreurs.
- Structurez les titres : les citations utilisent les titres pour inspirer confiance.
- Automatisez les mises à jour : un webhook ou une automation peut relancer l’ingestion après chaque publication.
- Utilisez les tags : facilitez le filtrage (ex.
{"audience": "manager"}).
Gestion des versions
- Hestyna conserve la dernière version ingérée. Modifiez et resynchronisez pour remplacer.
- Les index gardent trace de la date de mise à jour (
last_synced_at). - Pour l’audit, exportez la table des documents depuis Connaissance → Export.
Retrait de contenu
- Localisez le document dans Connaissance → Documents.
- Cliquez sur Retirer pour rendre le document inactif immédiatement.
- Planifiez une resynchronisation pour supprimer définitivement du moteur.
En pratique :